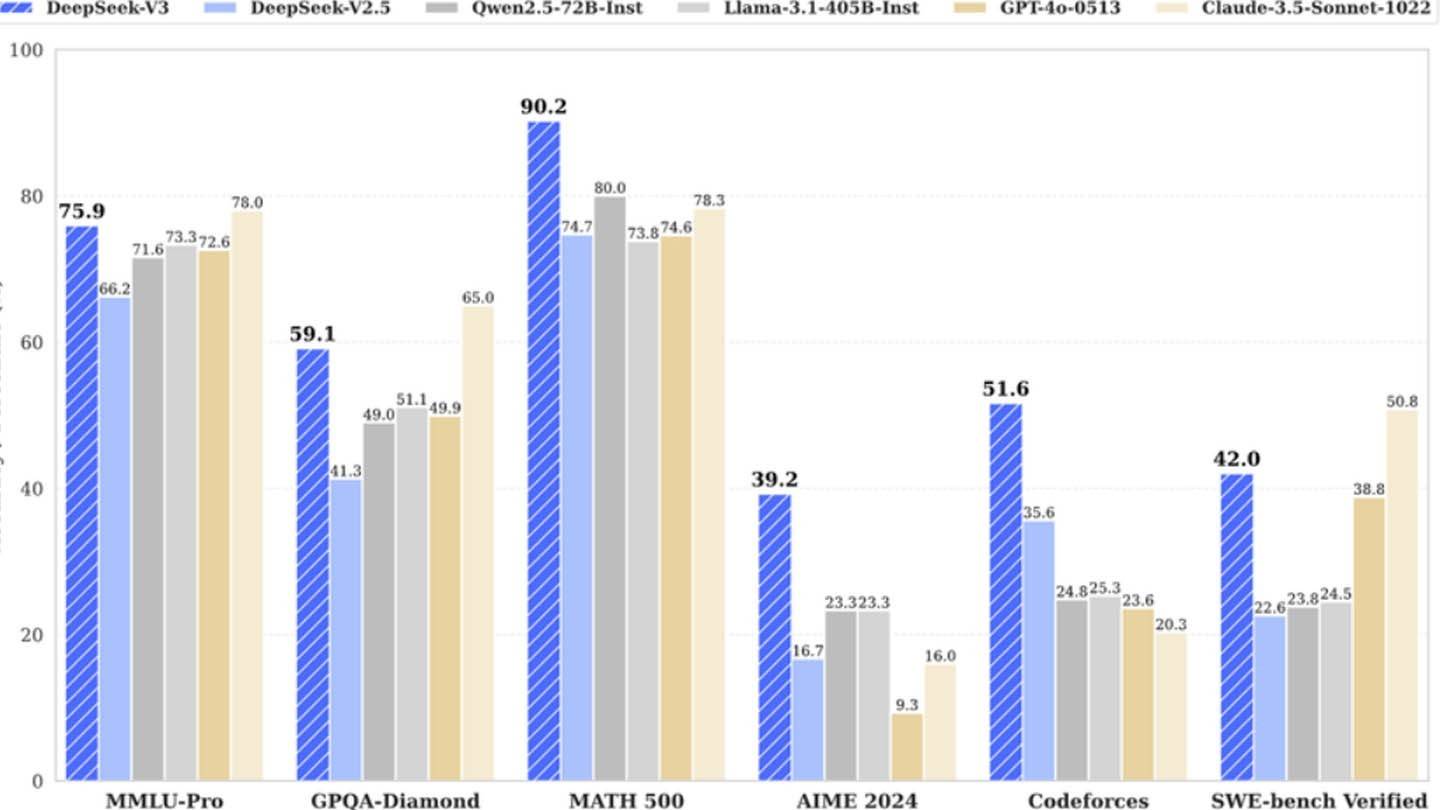
Новый чат -бот DeepSeek может похвастаться впечатляющим введением: «Привет, я был создан, чтобы вы могли спросить что угодно и получить ответ, который может даже удивить вас». Этот ИИ, продукт китайского стартапа DeepSeek, быстро стал основным игроком на рынке, даже способствуя значительному снижению цены акций Nvidia. Его успех проистекает из уникальной методологии архитектуры и обучения, включающей несколько инновационных технологий.
Multi-Token Production (MTP): в отличие от традиционного прогнозирования слов за словесным прогнозом, MTP прогнозирует несколько слов одновременно, анализируя различные части предложений для повышения точности и эффективности.
Смесь экспертов (MOE): эта архитектура использует несколько нейронных сетей для обработки входных данных, ускорения обучения ИИ и повышения производительности. DeepSeek V3 использует 256 нейронных сетей, активируя восемь для каждой задачи обработки токенов.
Многопользовательское скрытое внимание (MLA): MLA фокусируется на важных элементах предложения, неоднократно извлекая ключевые детали из фрагментов текста, чтобы минимизировать потерю информации и захватить тонкие нюансы.
Глубокопочтенный, первоначально потребовал удивительно низкую стоимость обучения в 6 миллионов долларов для своей мощной модели Deepseek V3, используя только 2048 графических процессоров. Тем не менее, полуанализа выявил гораздо более существенную инфраструктуру: приблизительно 50 000 графических процессоров Nvidia Hopper (включая 10 000 H800, 10 000 H100 и дополнительные графические процессоры H20), распределенные по нескольким центрам обработки данных. Это приводит к инвестициям в сервер в размере примерно 1,6 миллиарда долларов, а эксплуатационные расходы оцениваются в 944 миллиона долларов.
Deepseek, дочерняя компания Китайского хедж-фонда High-Fund, владеет своими центрами обработки данных, в отличие от многих стартапов, которые полагаются на облачные сервисы. Это обеспечивает больший контроль над оптимизацией и более высокой инновационной реализацией. Самофинансируемая природа компании повышает гибкость и скорость принятия решений. Кроме того, DeepSeek привлекает лучших талантов, некоторые исследователи зарабатывают более 1,3 миллиона долларов в год, в первую очередь набираясь из ведущих китайских университетов.
Первоначальная цифра в 6 миллионов долларов, поясняет DeepSeek, отражает только предварительные затраты на графический процессор, исключая исследования, уточнение, обработку данных и общую инфраструктуру. Общая инвестиция компании в развитие искусственного интеллекта превышает 500 миллионов долларов. Несмотря на эти существенные инвестиции, оптимизированная структура DeepSeek позволяет эффективно реализовать инновации.
Успех DeepSeek подчеркивает конкурентный потенциал хорошо финансируемой независимой компании по искусству. Хотя утверждение «революционного бюджета», возможно, преувеличено, достижения компании неоспоримы, в результате значительных инвестиций, технологических прорывов и сильной команды. Контраст является резким при сравнении затрат на обучение: DeepSeek R1 стоит 5 миллионов долларов, а CHATGPT4 стоит 100 миллионов долларов-обменоотражает относительную экономическую эффективность DeepSeek, даже с его значительными общими инвестициями.