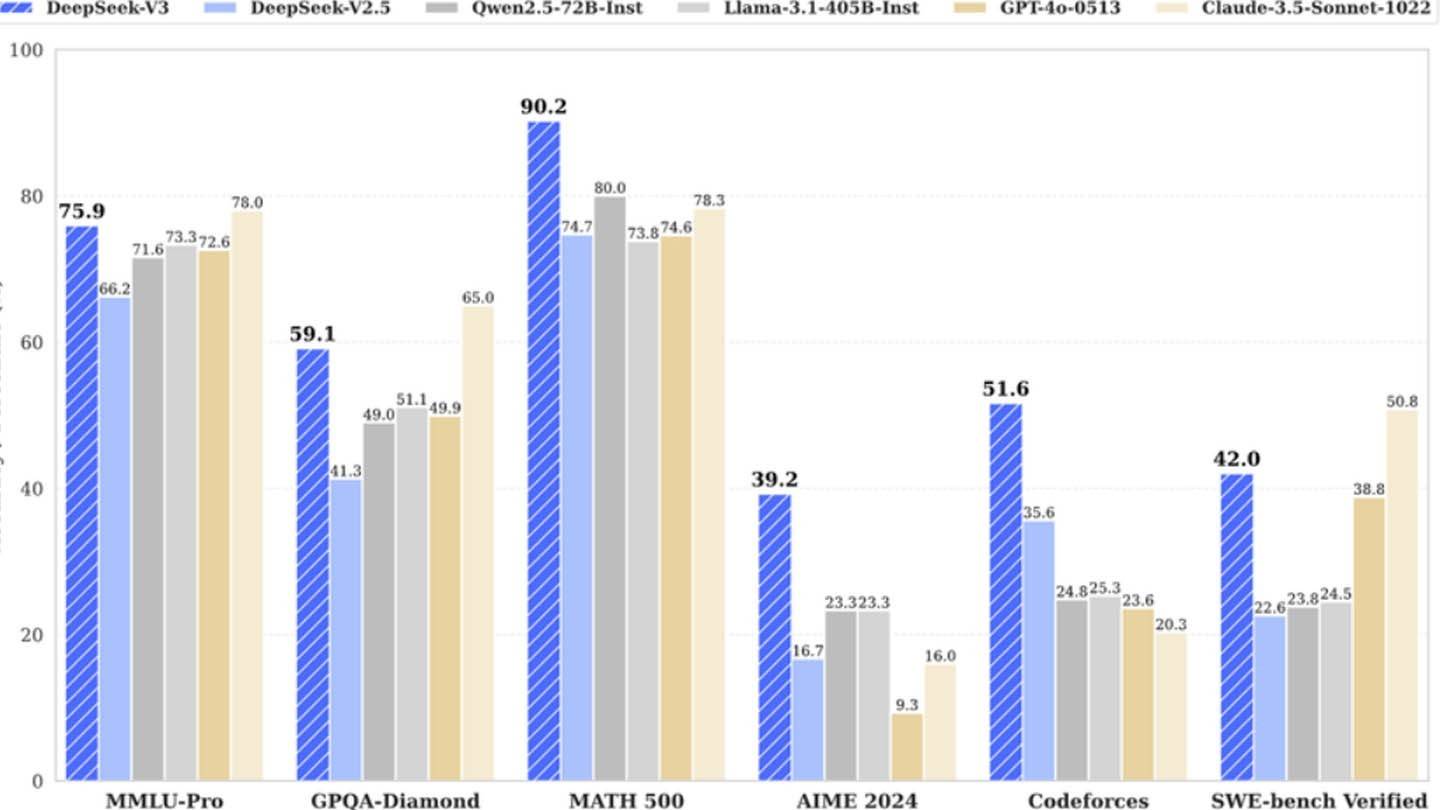
Deepseekの新しいチャットボットには、印象的な紹介があります。中国のスタートアップDeepseekの製品であるこのAIは、すぐに主要なマーケットプレーヤーになり、Nvidiaの株価の大幅な低下に貢献しています。その成功は、いくつかの革新的な技術を組み込んだユニークなアーキテクチャとトレーニング方法論に由来しています。
マルチトークン予測(MTP):従来の単語ごとの予測とは異なり、MTPは複数の単語を同時に予測し、さまざまな文章を精度と効率の向上について分析します。
専門家(MOE)の混合:このアーキテクチャは、複数のニューラルネットワークを利用して入力データを処理し、AIトレーニングの加速、パフォーマンスの向上を利用しています。 Deepseek V3は256個のニューラルネットワークを採用しており、トークン処理タスクごとに8個のアクティブ化されています。
マルチヘッド潜在的注意(MLA): MLAは重要な文化要素に焦点を当て、テキストフラグメントから重要な詳細を繰り返し抽出して、情報の損失を最小限に抑え、微妙なニュアンスをキャプチャします。
Deepseekは、2048 GPUのみを使用して、強力なDeepSeek V3モデルに対して600万ドルのトレーニングコストが非常に低いと主張しました。ただし、セミアンアリシスにより、はるかに重要なインフラストラクチャが明らかになりました。複数のデータセンターに分布している約50,000個のNVIDIAホッパーGPU(10,000 H800、10,000 H100、および追加のH20 GPUを含む)。これは、サーバー投資が約16億ドルで、運用費用は9億4,400万ドルと推定されます。
Chinese Hedge Fund High-Flyerの子会社であるDeepseekは、クラウドサービスに依存する多くのスタートアップとは異なり、データセンターを所有しています。これにより、最適化とイノベーションの実装を高めることをより強力に制御できます。同社の自己資金による性質は、柔軟性と意思決定速度を向上させます。さらに、Deepseekはトップの才能を引き付け、一部の研究者は年間130万ドル以上を稼ぎ、主に中国の大学から募集しています。
Deepseekの最初の600万ドルの数値は、研究、洗練、データ処理、および全体的なインフラストラクチャを除く、トレーニング前のGPUコストのみを反映しています。同社のAI開発への総投資は5億ドルを超えています。この実質的な投資にもかかわらず、DeepSeekの合理化された構造により、効率的なイノベーションの実装が可能になります。
Deepseekの成功は、資金提供された独立したAI企業の競争の可能性を強調しています。 「革新的な予算」の請求は間違いなく誇張されていますが、同社の成果は否定できず、重要な投資、技術的ブレークスルー、強力なチームに起因します。トレーニングコストを比較するとコントラストが厳しくなります:DeepseekのR1の価格は500万ドル、ChatGPT4は報告された1億ドルの費用がかかります。